论文链接
基于知识协同微调的低资源知识图谱补全方法
2022年3月发表于软件学报
是浙大prompt系列的一个延续
本文之前的工作:
AdaPrompt: Adaptive Prompt-based Finetuning for Relation Extraction
本文之后的工作:
Knowledge-aware Prompt-tuning with Synergistic Optimization for Relation Extraction
Relation Extraction as Open-book Examination: Retrieval-enhanced Prompt Tuning
与本文类似的也是用prompt做补全的论文:
Do Pre-trained Models Benefit Knowledge Graph Completion? A Reliable Evaluation and a Reasonable Approach
由清华提出来,发表于2022ACL
Introduction
![]()
基于知识指在进行模板构造时利用到手工模板。
协调微调指的是先调整模板和表达器最,等其收敛后再调全部参数。
低资源是因为prompt善于处理少样本学习任务。
然后整个模型是一个补全模型。
现有的知识图谱补全工作大多会假设知识图谱中的实体或关系有充足的三元组实例。
在通用领域,存在大量长尾三元组;在垂直领域,较难获得大量高质量的标注数据。
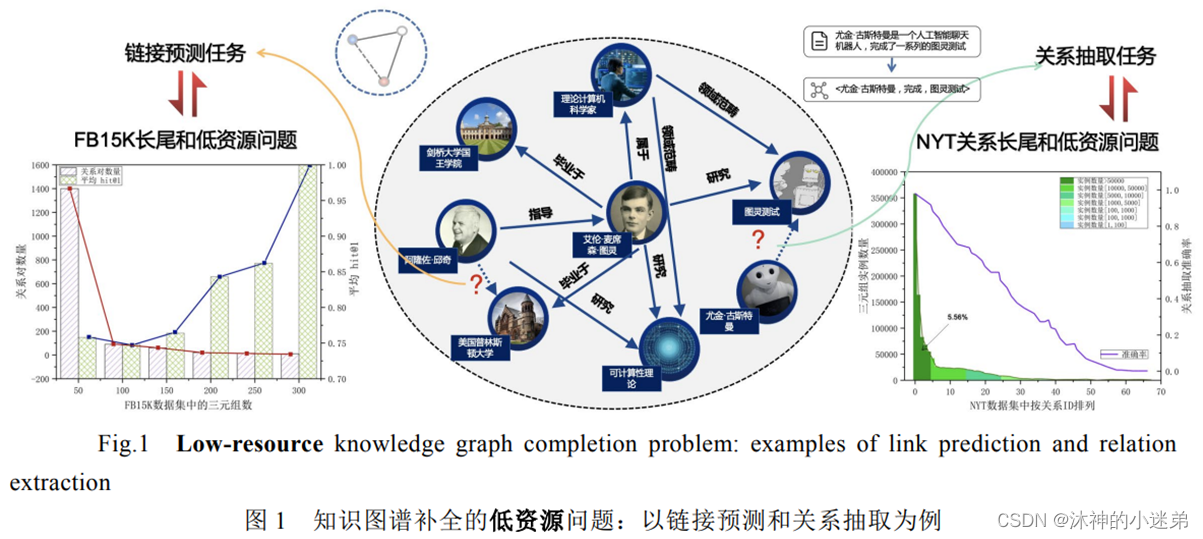
在关系抽取的补全任务中,预测精度随着关系的样本数目减少而大幅下降。
知识图谱补全可以通过知识图谱的链接预测或者从语料文本中抽取新的关系来实现。
不同于这些工作,本文主要借助外部知识来构建提示,并在知识图谱补全任务中同时考虑知识图谱的显式知识和语言模型隐式知识。

对于prompt类型文章,我们还是从基线模型、模板、表达器、目标函数来看。
基线模型
文章表示模型适用于很多预训练模型,本文主要介绍的是bert。
模板(软硬结合、搜索)
![]()
将模板初始化为这样子,然后对其进行编码:
![]()
![]()
得到hi,可学习的词向量参数:
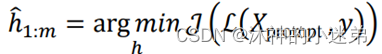
最后优化它们。
表达器(离散、搜索)
![]()
![]()
![]()
本文将BERT模型原先词表中的“[unused]”字替换成为本文的特殊标签字。
Method –协同学习算法 & 目标函数
总的来说,本文有两个目标函数:
关系判别目标函数𝒥R 和 实体判别目标函数𝒥E
关系判别函数让模型能够拟合在本文知识图谱补全任务的数据集上。
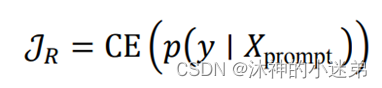
实体判别目标来训练通过句子中的其他信息理解实体的意思。
在模型输入中随机掩盖一个实体,然后利于预训练任务目标让语言模型去预测该实体。
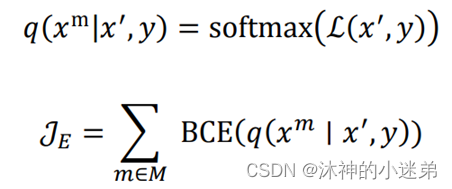
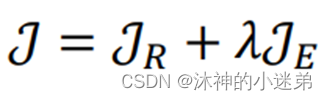

1.首先基于知识驱动的模板构建和标签组合得到初始的提示(Prompt),并随机初始化其余部分待优化模板词和标签。
2.然后固定原始模型的所有参数,并只优化模板特殊字以及标签词特殊字{ℎ1, … , ℎ𝑚𝑚, . . , ℎ𝑚𝑚+𝑛𝑛}(3-7 行)。
3.最后,优化模型全部的参数。(8-12 行)
Experiment
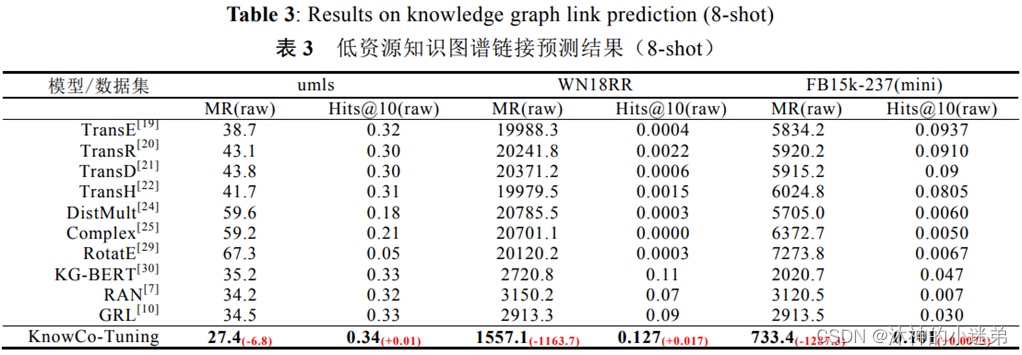
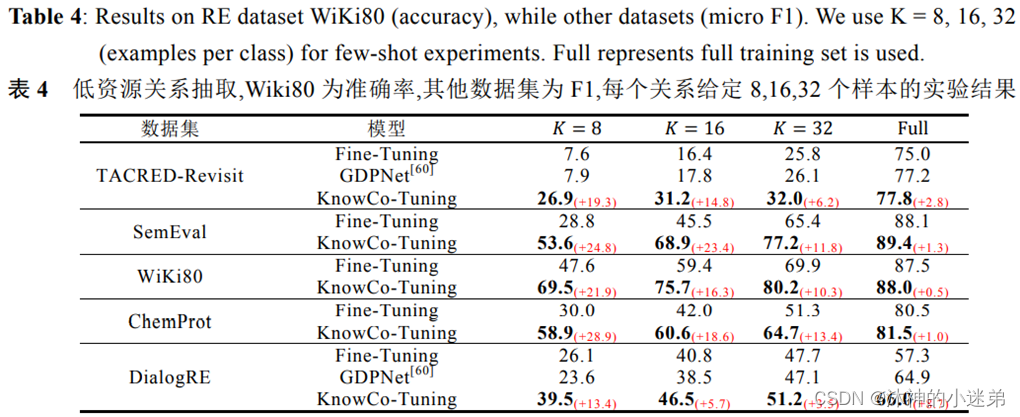
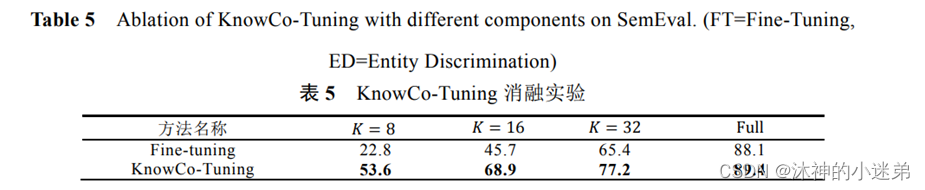

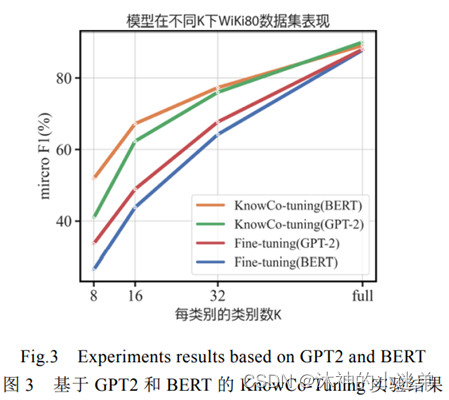
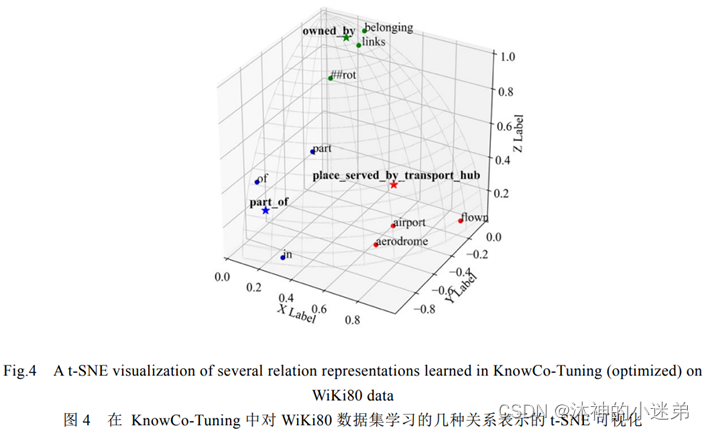
实验效果的话大致就是讲首先补全和关系抽取的效果好,其次prompt方法适合小样本学习,再就是虚拟标签词在3维空间与真实类别的语义距离近,然后就是消融实验证明每一个模块有效。
Comparison
与清华的PKCG对比:
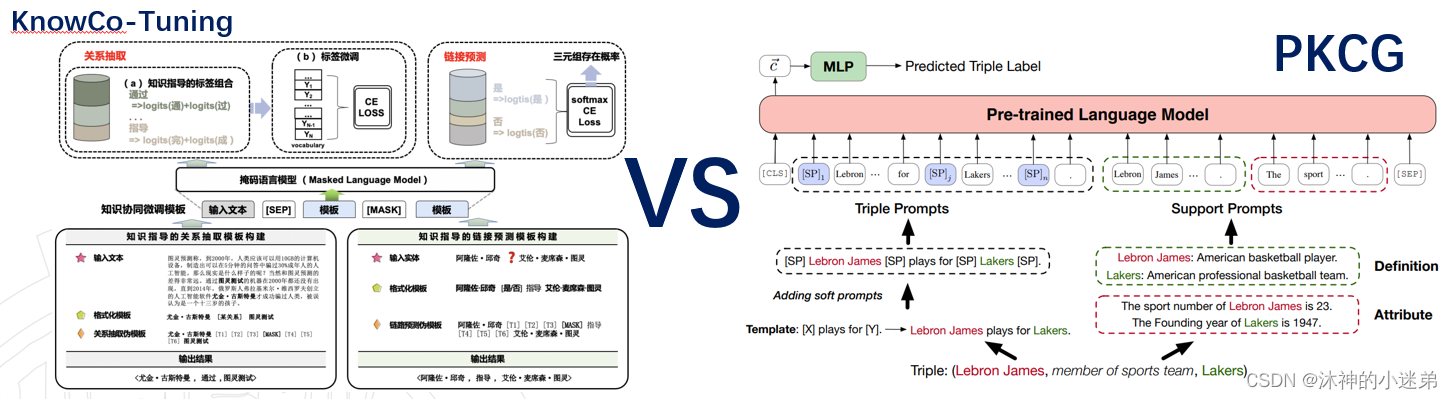
1.PKCG使用分类头,KnowCo-Tuning使用表达器。
2.PKCG有额外的支持模板增强语义。
3.PKCG专门为每个关系类别设计模板。
4.两个模板都用到soft-prompt。
5.KnowCo-Tuning可解释性差。
6.PKCG效果更好。
其中2和3都更好的利用语言模型的属性,模型效果有没有被规则限制待验证。
总结
总的来说这篇文章是比较早的prompt方式了,并且可解释性差,如果做这方面的工作可以再看看清华他们的PKCG,另外用预训练模型&prompt做关系抽取和图谱补全的任务相似,一般关系抽取的方法效果好,做补全可以把关系抽取的方法拿过来。