Relation Extraction as Open-book Examination: Retrieval-enhanced Prompt Tuning
浙大基于prompt的关系抽取最新论文,刷新prompt方法的SOTA。
因为之前对prompt类关系抽取方法已经做了很多介绍,所以现在直接看方法。
BACKGROUND
对于难度较大的实例,PLMs通常不能很好地泛化,并且在训练过程中,由于模型嵌入中稀缺的数据或复杂的实例不容易记忆,导致PLMs在资源极低的环境下运行不稳定。
本文将RE视为一种开卷考试,提出了一种检索增强的半参数关系抽取提示调整范式。我们构建了一个open-book数据存储库,将基于提示的实例表示和对应关系标签作为记忆的键值对用于检索。在推理过程中,该模型通过将PLM的基本输出与数据存储上的非参数最近邻分布线性插值来推断关系。这样,我们的模型不仅可以通过训练时存储在权值中的知识来推断关系,而且可以通过在开卷数据存储中展开和查询示例来辅助决策。
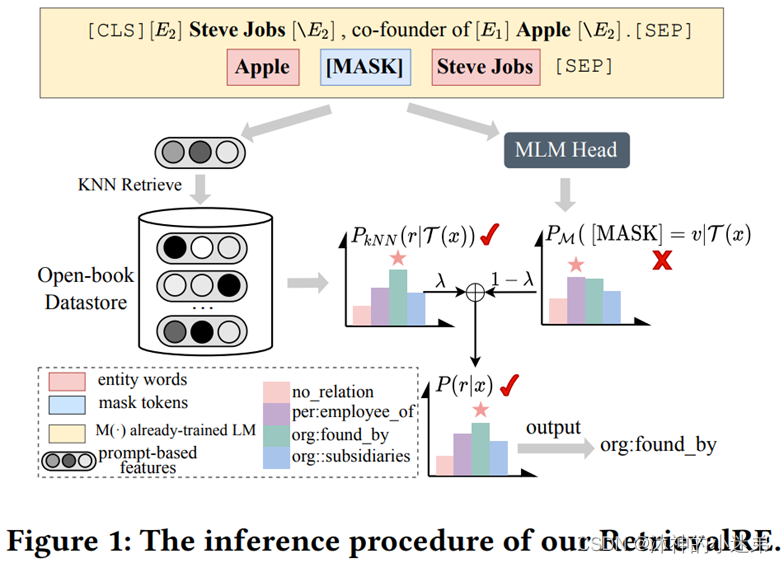
METHODOLOGY
用于检索的 Open-book Datastore
Open-book Datastore的构造主要包括基于提示的实例表示和数据存储集合。
采用[MASK]的隐藏向量作为基于提示的实例表示𝒉𝒄
![]()
𝑷𝑳𝑴最后一层的[MASK] token的输出嵌入可以有效地利用在预训练期间学习到的显式知识。
利用训练集上基于提示的实例表示来构建数据存储
![]()
𝒉𝒄𝒊是上一步计算的上下文嵌入,𝒓𝒊是关系。
检索增强的关系预测
采用欧氏距离计算𝒉𝒙和𝒉𝒄𝒊的距离:

在负距离上应用𝒔𝒐𝒇𝒕𝒎𝒂𝒙函数来计算邻居的分布,形成对预定义关系的一个概率分布。
通过插值非参数𝑘最近邻分布𝑷𝒌𝑵𝑵与已经训练好的𝑷𝑳𝑴的𝑴𝑳𝑴预测𝑷𝑴使用参数𝝀来生成关系的最终概率来重构𝑷(𝒓|𝒙) 。
![]()
EXPERIMENTS